How to get href value of each a tag from the html using python Beautiful Soup
import requests
from bs4 import BeautifulSoup
link = "http://www.flipkart.com/mobiles?otracker=hp_header_nmenu_sub_Electronics_0_Mobiles"
doc = requests.get(link)
soup = BeautifulSoup(doc.text, 'html.parser')
main_div = soup.find(id="list-tagcloud")
div2=main_div.find_all('div')[1]
links = div2.find_all('a')
for link in links:
print link.attrs.get('href')
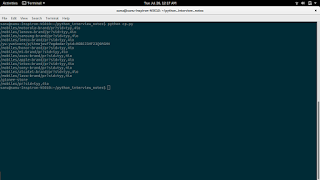
OUTPUT
======
/mobiles/motorola~brand/pr?sid=tyy,4io
/mobiles/lenovo~brand/pr?sid=tyy,4io
/mobiles/samsung~brand/pr?sid=tyy,4io
/mobiles/leeco~brand/pr?sid=tyy,4io
/yu-yunicorn/p/itmejeuf7egdedar?pid=MOBEJ3MF23Q9MGMH
/mobiles/honor~brand/pr?sid=tyy,4io
/mobiles/mi~brand/pr?sid=tyy,4io
/mobiles/asus~brand/pr?sid=tyy,4io
/mobiles/apple~brand/pr?sid=tyy,4io
/mobiles/intex~brand/pr?sid=tyy,4io
/mobiles/sony~brand/pr?sid=tyy,4io
/mobiles/alcatel~brand/pr?sid=tyy,4io
/mobiles/lava~brand/pr?sid=tyy,4io
/gionee-store
/mobiles/pr?sid=tyy,4io
from bs4 import BeautifulSoup
link = "http://www.flipkart.com/mobiles?otracker=hp_header_nmenu_sub_Electronics_0_Mobiles"
doc = requests.get(link)
soup = BeautifulSoup(doc.text, 'html.parser')
main_div = soup.find(id="list-tagcloud")
div2=main_div.find_all('div')[1]
links = div2.find_all('a')
for link in links:
print link.attrs.get('href')
OUTPUT
======
/mobiles/motorola~brand/pr?sid=tyy,4io
/mobiles/lenovo~brand/pr?sid=tyy,4io
/mobiles/samsung~brand/pr?sid=tyy,4io
/mobiles/leeco~brand/pr?sid=tyy,4io
/yu-yunicorn/p/itmejeuf7egdedar?pid=MOBEJ3MF23Q9MGMH
/mobiles/honor~brand/pr?sid=tyy,4io
/mobiles/mi~brand/pr?sid=tyy,4io
/mobiles/asus~brand/pr?sid=tyy,4io
/mobiles/apple~brand/pr?sid=tyy,4io
/mobiles/intex~brand/pr?sid=tyy,4io
/mobiles/sony~brand/pr?sid=tyy,4io
/mobiles/alcatel~brand/pr?sid=tyy,4io
/mobiles/lava~brand/pr?sid=tyy,4io
/gionee-store
/mobiles/pr?sid=tyy,4io

Comments
Post a Comment